
Introduction
Current Internet is composed of heterogeneous multi-AS (autonomous system) networks (wireless, optical networks etc.) as shown in Fig. 1. Wherein, 5G and optical passive networking (PON) have been recognized as the building blocks for next-generation access networks, while elastic optical networking (EON) is emerging as one of most promising technologies for future backbone networks due to its fine-grained and agile spectrum allocation schemes. With the rapid development of datacenter networks and the explosion of cloud-driven applications, future Internet is expected to be able to support dynamic, high-capacity and quality-of-transmission aware end-to-end services across domains. Due to the inherent complexity in optimizing service provisioning in optical networks and the heterogeneity and autonomy of ASes, current networking designs relying on artificially defined rules are becoming the main factors restricting the network-wide performance and hindering the evolutions of the Internet. Therefore, we envision a powerful network control and management (NC&M) system equipped with self-learning, self-adapting and self-healing capabilities to meet the challenges of the next-generation Internet.
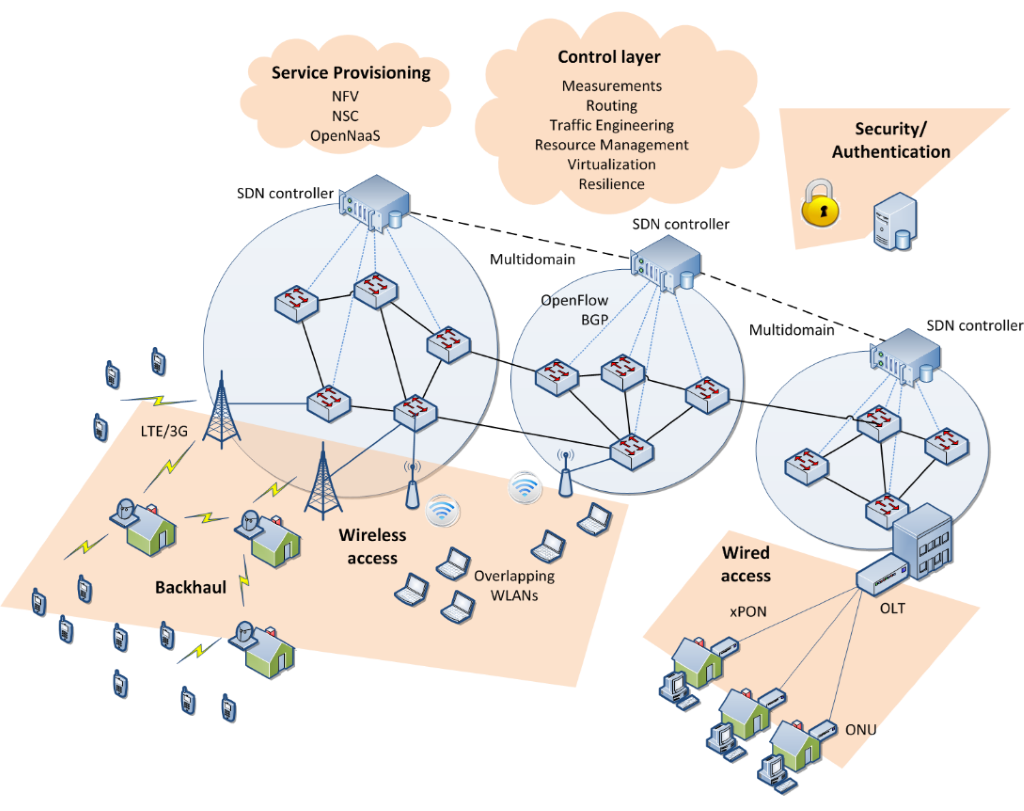
Fig. 1 Internet Infrastructure [1].
Research Activities
Network Architectural Design: In this research, we perform architectural studies on self-driving autonomic optical networking systems, including the required system function modules and working flows. Fig. 2 shows the block diagram of the proposed DRL-based autonomic networking framework. The framework is built on the basis of the software-defined networking (SDN) architecture, with decoupled data and NC&M planes. The data plane adopts EON technologies to provision dynamic and flex-grid (e.g., at a granularity of 6.25 GHz) optical connections for clients from metro networks, datacenters, and research facilities. Optical performance monitoring functionalities (e.g., monitoring of optical signal-to-noise ratio) are also employed for sensing the states of data plane operations. The NC&M plane employs a remote and centralized SDN controller for service provisioning management. The SDN controller utilizes advanced network modeling languages and SDN protocols to communicate with SDN agents (locally attached to data plane equipment) for collecting service requests, distributing service schemes, and inquiring device conditions and monitoring data on demand. We design the service provisioning mechanism based on the principle of deep reinforcement learning (DRL). Specifically, upon an event (e.g., reception of a service request) that triggers a specific DRL application (e.g., DRL-based routing and spectrum assignment or failure restoration), the SDN controller makes the feature engineering module generate an EON state representation for the corresponding DRL agent. The feature engineering module retrieves various network state data (such as pending requests, in-service connections, and resource utilization) from the traffic engineering database and tailors the data to meet the demand of the DRL agent. The deep neural networks (DNNs) of the DRL agent take as input the state data and output a service provisioning policy to the SDN controller. Here, a service provisioning policy can be a probability distribution over a set of available service schemes. The SDN controller in turn determines a service scheme with the policy. Based on the service provisioning outcome, corresponding feedbacks are sent to the reward system. The reward system translates the feedbacks into an immediate reward for the DRL agent. The reward enables the DRL agent to quantitatively measure the quality of the action taken (i.e., the service scheme selected). For example, an agent gets a reward of ‘1’ if a request is successfully serviced, and ‘0’ otherwise. The service provisioning sample (i.e., the state, action, and reward tuple) is stored in the experience buffer, which afterward produces training signals to update the DNNs. In particular, the DRL agent tunes the DNNs to reinforce actions (i.e., increase the corresponding probabilities) leading to higher long-term cumulative rewards. This way, through repeated service provisioning practice, the DRL agent can progressively learn effective policies. Meanwhile, as the DRL agent performs training constantly upon new observations, it is able to adapt to gradual network evolutions. Different DRL agents can also work in collaboration through knowledge transfers for faster convergence and improved network-wide performance. Eventually, the DRL-based service provisioning design enables a fully autonomic EON system with self-learning and self-adapting capabilities. Note that, with slight modifications, the proposed framework is also applicable for networks using different data plane technologies (e.g., packet networks).
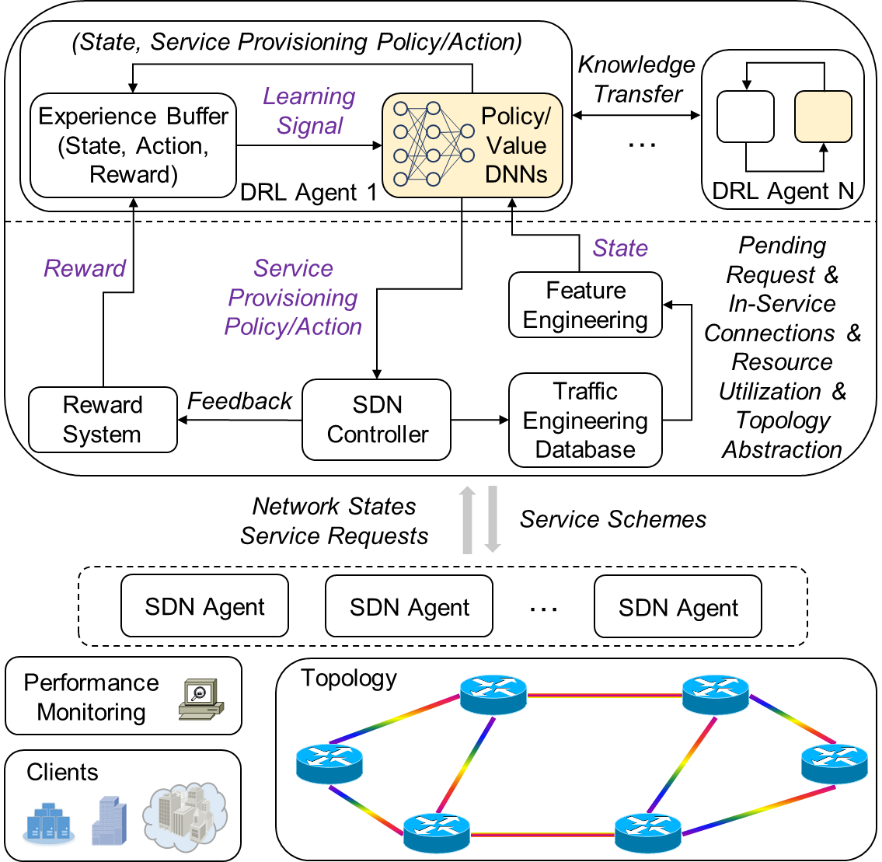
Fig. 2. Schematic of self-driving autonomic optical networking system.
Service Provisioning Policy Design: We have performed studies on designing autonomic routing and spectrum assignment (RMSA) agents (called DeepRMSA) based on the proposed autonomic networking framework. Fig. 3 shows an example of RMSA operations in EON, where two lightpath requests R_1 (from node 1 to node 4) and R_2 (from node 2 to node 5) arrive sequentially, each demanding for bandwidth of 2 or 4 frequency slots (FS’s). For the sake of clarity, we reduce the optimization dimension of the RMSA problem by fixing the routing paths as 1-2-4 and 2-4-5, respectively, and omitting the modulation format assignment procedure. Based on the spectrum utilization state on each link, two FS-blocks (i.e., [1,5] and [9,10]) are available on path 1-2-4. However, the only correct policy is allocating FS-block [9,10] to R_1 (where both of the requests are successfully serviced), since otherwise, R_2 will be blocked due to the lack of spare spectra on link 2-4. Note that, more practical RMSA problems involving realistic-scale topologies and larger link capacities while allowing flexible routing and modulation format choices would be much more complicated than that given by the above example.
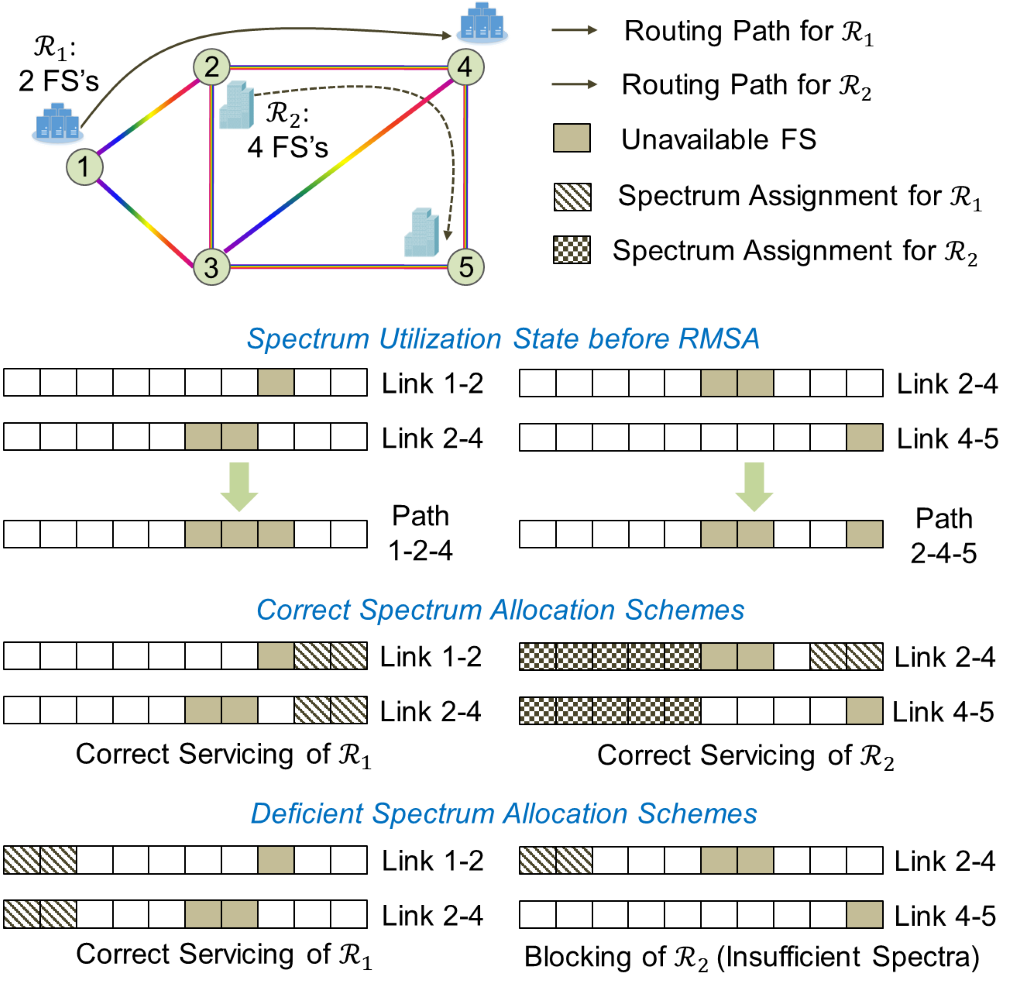
Fig. 3. An example of RMSA operations in EON.
In our design, we make the DeepRMSA agents read information of lightpath requests (source, destination nodes, bandwidth requirements, service duration) and the spectrum utilization state on K shortest candidate routing paths. For each path, we compute the number of FS’s required based on an impairment-aware model, the total number of available FS’s, the average size of available FS blocks (consecutive available FS’s), and the size and starting position of the first available FS block. We adopt a fully-connected DNN consisting of five hidden layers of 128 neurons and a single-layer policy and value heads. An agent receives a reward of 1 or -1 if a lightpath request is successfully serviced or is rejected. For more details of the training process, please refer to our work in [2]. Fig. 4 plots the results of request blocking probability, where SP-FF and KSP-FF are baselines algorithms found as the state of the art. It can be seen that DeepRMSA successfully beats both of the baselines after training of around 30,000 epochs and eventually can achieve a blocking reduction of 45.9% compared with KSF-FF. The average spectrum utilization ratios from DeepRMSA (after training of 200,000 epochs), KSP-FF and SP-FF are 32.6%, 30.4%, and 27.2%, respectively. Since DeepRMSA enables to accommodate more requests, it utilizes the largest amount of spectrum resources.
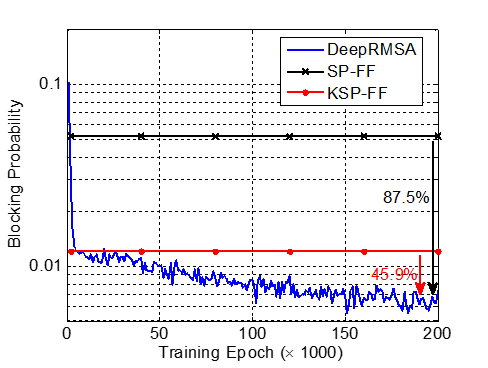
Fig. 4. Results of request blocking probability during the learning process.
System design and implementation: This resarch also aims at designing and implementing a self-driving autonomic prototype system for verifying the proposed designs, as shown in Fig. 5 for a two-domain seven-node SD-EON network testbed. The first domain has a star-ring architecture that consists of four nodes, while the second domain has a three-node ring architecture. Each node is connected to other nodes by spools of single-mode fiber (SMF) or dispersion shifted fiber (DSF) of different lengths (15, 20, and 25 km). A 10 GBd 16-QAM coherent transmitter generates the testing signal used for data training and prediction. This signal is multiplexed with 20 50 GHz spacing 10 Gb/s dense wavelength division multiplexing (DWDM) on-off keying (OOK) signals, serving as the background traffic. The signal at the output of the multiplexer is injected into the testbed. The optical spectrum analyzer (OSA)-based OPMs are placed at the inputs of each node to monitor the optical power and the spectrum occupancy of background traffics.
The collection of training and evaluation datasets was achieved by enumerating each of the possible routing paths. We applied random routing for the background traffic and random attenuations (0 dB–7 dB for each WSS) for all the signals to purposely introduce perturbations to the network and allowing to sample the entire input space of the unknown target function that correlates the QoT and OPM readings. The launch power of each fiber span varies from −7 dBm to 12 dBm depending on the random applied attenuation and routing at each WSS node. At each run, we measured the actual Q-factor of the testing signal at Node G and record this value as the label of the current dataset. We implemented the domain manager-level ANNs and broker-level ANNs of 25 hidden units. For benchmarking purpose, we also implemented an omniscient ANN that can access all the OPM data of the two domains. Fig. 6 shows the training and Q-factor prediction performance of the omniscient and hierarchical estimators for one of the routing path. Both ANNs converge properly without overfitting. The Q-factor deviations for the omniscient and hierarchical estimators are 0.5 and 0.52 dB, respectively. From Figs. 6(a) and (b), the hierarchical estimator seems to have a slower convergence speed and slightly higher out-of-sample error against the omniscient ANN. These results indicate that the proposed hierarchical estimator can achieve nearly ideal QoT prediction performance (with a small penalty) while supporting the autonomy and privacy of each autonomous domain.
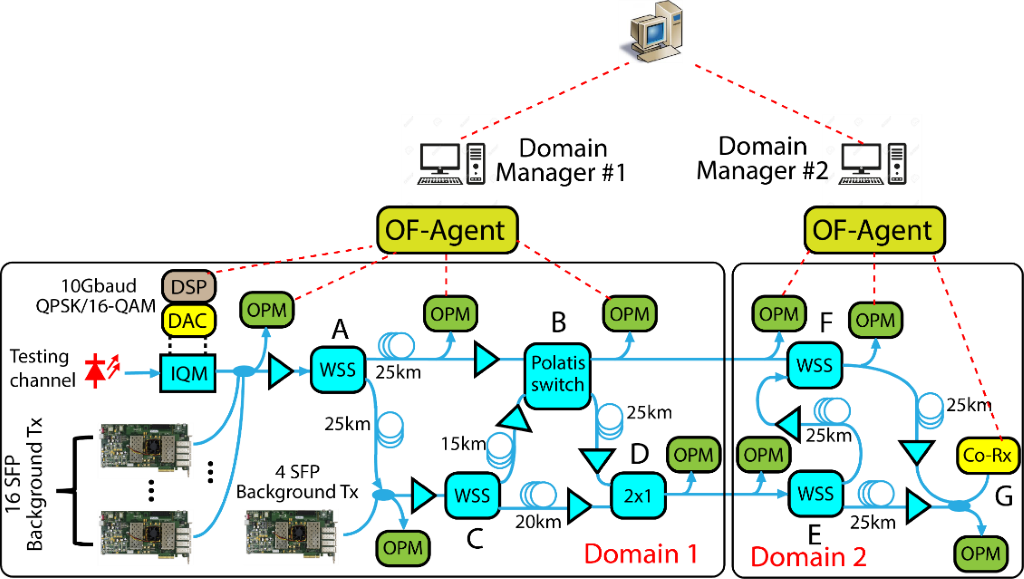
Fig. 5. Our field test experimental testbed. DSP: digital signal processing; DAC: digital-to-analog converter; IQM: I/Q modulator; OF-Agents: openflow agent; WSS: wavelength selective switch; Co-Rx: Coherent receiver; SFP: small-form factor pluggable.
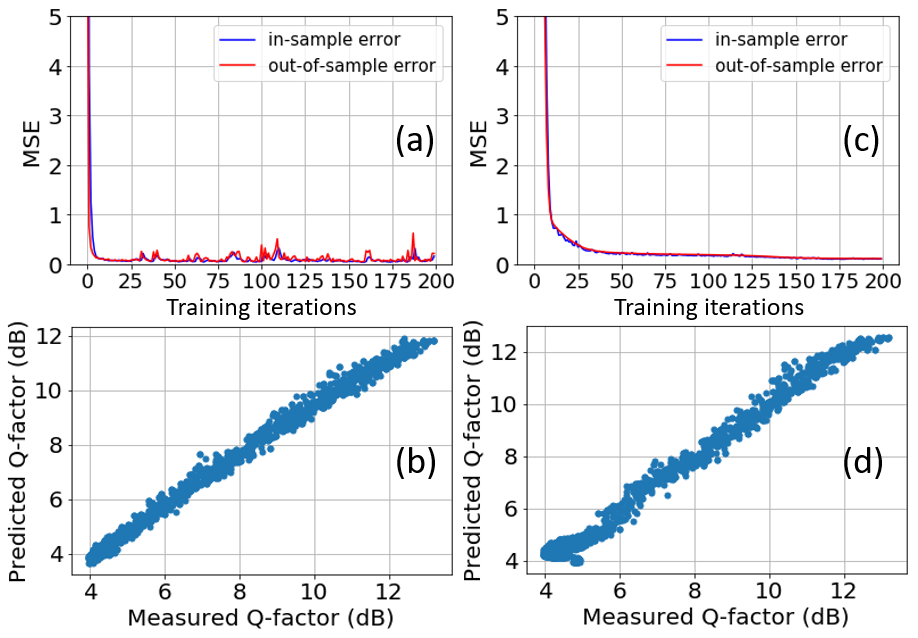
Fig. 6. Inter-domain learning performance: (a) MSE vs. training iterations for omniscient estimator; (b) QoT prediction accuracy for omniscient estimator; (c) MSE vs. training iterations for hierarchical estimator; (d) QoT estimation accuracy for hierarchical estimator.
References
[1] https://esdn.upc.edu/en
[2] “DeepRMSA: A Deep Reinforcement Learning Framework for Routing, Modulation and Spectrum Assignment in Elastic Optical Networks”, X. Chen et al., IEEE JLT, 2019.
[3] “Hierarchical learning for cognitive end-to-end service provisioning in multi-domain autonomous optical networks”, G. Liu et al., IEEE JLT, 2019.